On the General Architecture of the Peer Web (and the placement of the PC 2.0 era within the timeline of general computing and the greater socioeconomic context)

There have been three eras of general computing… the fourth remains to be written.
A highly-compressed overview of the history of general computing
The first era of general computing was the mainframe era and it was centralised. The second, the personal computing (PC 1.0) era, was decentralised. The third is the Web era (let’s call it Mainframe 2.0). And it is, once again, centralised. Today, we find ourselves at the end of the Mainframe 2.0 era and on the precipice of a new chapter in the history of general computing: the Peer Web. Let’s call it the Personal Computing 2.0 (PC 2.0) era.
On taxonomic criteria and the greater context
The primary characteristics that determine our taxonomy of the four eras of computing are ownership and control, reach, and network topology. However, these neither exist in a vacuum nor do they emerge spontaneously.
Technology is an amplifier. What technology amplifies – in other words, the character of our technologies – is determined by the social, economical, and ideological context that funds and produces it to realise its objectives. Any taxonomy of technological artifacts not grounded in socioeconomics is akin to a classification of life devoid of evolutionary theory. Without understanding the social, economical, and ideological forces that forge our technologies, we cannot understand their true purpose beyond that which is stated by the marketing departments of the organisations that produce them.
Furthermore, given that technology is a multiplier, a crucial question for the future of humanity is what exactly is it multiplying? Given that the rate of change in technological progress is exponential, and given that this translates to an exponential increase in our ability to impact our own habitat, it is essential that we are able to answer this question correctly. And if we find that the feedback loop between our ideologies and their realisations (as enabled by the technologies they sponsor) are leading to outcomes that range from undesirable to catastrophic – from radically reduced freedom and human welfare at the optimistic end of the scale to extinction of our species at the other – then we must alter our ideologies and socioeconomic success criteria and ensure that technological infrastructure exists to amplify those more sustainable alternatives.
I must also state that I am not optimistic about our chances of effecting the change we need to stave off the worst outcomes. I am, at most, cautiously hopeful. This is part of a far more fundamental battle that rages inside of each of us: the struggle between our base and higher-order evolutionary traits (both of which have made us who we are today). Our base evolutionary traits once facilitated our survival in times when resources were scarce and our agency within our environment was limited. Yet, today, left unrestrained, they lead us to obesity and self-harm at the species scale. And yet we also possess higher-order evolutionary traits that manifest as our ability to forgo instant gratification. We have been known to reject the next readily available source of glucose and dopamine and engage in acts of enlightened self interest. These have translated into our forming societies, caring for others, and the creation of social safety nets. These higher-order evolutionary traits have had as much (if not perhaps a far greater in later times) impact on the success of humanity as a social species. If we care about our own freedom and welfare as individuals and as a society at the lower end of the scale and the survival of the species at the higher end, we must shun the former and embrace the latter traits. It remains to be seen if we are capable of doing so or whether the current levels of inequality within our systems have already crossed a tipping point beyond which they self perpetuate ad perniciem.
Finally, any analysis that overlooks the irrationality woven into the very fabric of our society cannot hope to make sense of the nonsense that shapes much of our current ideology, and, thus, gets translated into policy. These nonsensical aspects are, ironically perhaps, as scientifically grounded in the same evolutionary process I mentioned earlier. Irrationality simply wasn’t a negative evolutionary trait when our technological capabilities limited its potential fallout to a statistically-insignificant percentage of our habitat or our species. Back when, we could at most destroy cities and, at our most barbaric, kill some millions. Even with our relatively modest technology during the colonial era, however, it turns out that we managed genocide on such a scale that it led to a period of global cooling. Today, we have the technological capability to destroy our habitat and wipe out our species several times over. And it would be folly to assume that the ideologies that shape our policies and determine our success criteria, which fund our technologies, which realise our ideologies are in any way based on reason, enlightened self interest, or even a fundamental desire to survive or thrive in anything but the extreme present. Our current feedback loop incentivises, rewards, breeds, and elevates to great power and wealth the most sociopathic/psychopathic, shortsighted, and self-destructive of behaviours and the people that embody them. To break such a loop, we must look not only at which rational levers to adjust to alter our socioeconomic success criteria but also which irrational clutches prevent us from doing so. To put it simply, we cannot avoid catastrophe as long as we believe that limitless, exponential growth is possible in a closed system with scarce resources. And we cannot impart the responsibility necessary to alter our behaviour as long as we believe that we do not actually possess catastrophic agency over our habitat because we ultimately attribute agency at such scale to a magical sky fairy.
All that said, all we can do is to concentrate on the change that we can effect. Blissful ingnorance will not get us anywhere but neither will abject hopelessness. We must compose a rational understanding of the problem and concoct sustainable alternatives that can be adopted should the will arise. Whether or not our alternatives are adopted or used is unknowable and, to a great extent, irrelevant. Because what we do know is that unless the alternatives exist – even in some basic prototypical form – it is guaranteed that they will not be adopted or used and that disaster is inevitable. All we can do is to make our case as clearly as we can, attempt to the best of our abilities to inform and educate, build the tools that can fix the problem, and generally be the change we want to see in the world. This does not require optimism, only realism with imagination. This is not philantrophy. It’s humanity’s struggle to survive past its a painful adolescence and emerge as a responsible adult. This is about getting us from celebrating sociopathically-extreme shortsightedness and greed as success to embracing enlightened self interest.
Now put all that aside (but always keep it in your little finger) and let’s return to our taxonomy of technology.
Mainframe 1.0
In the original mainframe era, ownership and control of computers was centralised to a handful of wealthy organisations (military, academic, and corporate). The direct reach of the network was similarly limited to the people in those organisations. That is not to say, of course, that the impacts of mainframe computing did not extend beyond the walls of those organisations. One need look no further than IBM’s partnership with the Third Reich for evidence of its worst ramifications. (If IBM could enable the Holocaust using punch-card mainframes, imagine what Alphabet, Inc. could do today with the technology it has.)
PC 1.0
The first personal computing era began circa 1976 with the Apple I. It was the first time that individuals got to own and control computers. It was also the last decentralised era of technology. While the primary reach of computing expanded far beyond institutional walls and entered our homes, what was noticeably lacking (beyond the rudimentary bulletin board systems – BBSes – that were the purview of a strict subset of enthusiasts) was a network to tie all these personal computers together and enable them (and us) to communicate. Information in the PC 1.0 era was exchanged the old-fashioned way… hand-to-hand using floppy disks. In the PC 1.0 era, individuals had ownership and control of their machines. If, for example, you installed an app and it used your 9600 baud modem to phone home and report on your behaviour, we called it a Trojan – and we understood it to be malware. Today, we call a far more sophisticated and ubiquitous version of this the extremely lucrative business model of Silicon Valley.
Centralised Web (Mainframe 2.0)
There is a common misconception (perhaps owing to its stated aims or a conflation with the nature of some of the fundamental protocols of the Internet) that the World Wide Web is decentralised. It is not and never has been.
The fundamental architecture of the Web has always been client/server. In other words, centralised. The Centralised Web era was, in effect, a return to mainframe computing. The only difference is that the mainframes are now global in reach. Our new mainframes are household names like Google, Facebook, and Snapchat (and lesser-known data brokers and surveillance companies that lurk behind the scenes like Acxiom and Palantir).
The Web today is an oligopoly of multinational corporations with business models based on surveillance and ownership of people by proxy. It was the Centralised Web that ushered in the socioeconomic system we call surveillance capitalism. Capitalism, of course, has always relied on some level of surveillance and ownership of people, all the way back to its basis in slavery. What is different today is the nature and scope of the surveillance and ownership.
It is crucial that we understand that even in the early days, the Web was centralised. The centres (the servers) were just closer to each other in size. That changed when the Web was commercialised. The injection of venture capital with its expectation of exponential returns for Vegas-style high-risk betting provided the enzymatic pool that incentivised the centres to grow in tumour-like fashion until we got the monopolies of Google, Facebook, and their ilk. A new era of people farming was born. And while we diagnosed the tumours early, instead of recognising them as a threat, we started celebrating them and paving the way for a new type of slavery by proxy to sneak in through this digital and networked backdoor. This new slavery, let’s call it Slavery 2.0, is not as crude as Slavery 1.0. In Slavery 2.0, we no longer need physical possession of your body. We can own you by proxy by obtaining and owning a digital copy of you.
Here’s how it works: The so-called consumer technologies of today, with few exceptions, have two facets. There is the face you see: the addictive, potentially useful one that you interact with as “the user” and the one you don’t see. The one that’s watching you and taking notes and analysing your behaviour so that it can use the intimate insight it gleams from this constantly-evolving profile of you as a digital proxy with which to manipulate and exploit you. In retrospect, the World Wide Web is a most fitting name for the construct that enabled this. It’s a web with a giant spider in the middle. The spider goes by many names… Google, Facebook, Snapchat…
It’s also no coincidence that the centralised Web evolved alongside a period of unprecedented global concentration of wealth and power within the hands of a tiny group of billionaires. Surveillance capitalism, after all, is the feedback loop between capitalism (accumulation of wealth) and surveillance (accumulation of information). Surveillance capitalism is what you get when those with accumulated wealth invest that wealth in systems that result in the accumulation of information within the same hands which they then exploit to accrue further wealth.
The power differential between the haves and the have nots in surveillance capitalism is compounded not just by a widening gap in the wealth of the former versus the latter but also by the information the former has on the latter. To put it simply, if I know everything about you and you know nothing about me, I essentially own you by proxy. If, further, I dictate the tools you use to experience the world around you, I get to filter (and thus create) your reality. In the film The Matrix, people’s minds inhabit a virtual reality while their bodies are farmed in physical space. On Earth, circa 2019, we inhabit a physical space while our minds are farmed from a virtual reality. But, as in any good science fiction story, there is hope that a band of plucky rebels might just turn the tide in the face of overwhelming odds… and that brings us to the present day where we find ourselves witnessing and helping shape the next era of technology: the Personal Computing 2.0 era.
Peer Web (PC 2.0)
Where the Centralised Web is client/server, the Peer Web is peer to peer. Unlike traditional peer to peer, however, the Peer Web makes use of unprivileged always-on nodes to solve two of the usability problems that have plagued traditional peer to peer systems: findability and availability.
In order to bootstrap the Peer Web, we must make the provision of personal always-on nodes at a universally-reachable and human-readable address a seamless process. In other words, we must make it trivial for anyone to sign up for and own a node (hosted either by a third party or themselves) that guarantees universal findability via a domain name as well as close-to-constant availability. These two requirements are non-negotiable as they form the bare minimum necessary to compete with the usability of centralised systems. On top of this, however, we can layer those aspects made possible by a peer-to-peer and end-to-end encrypted architecture: privacy and censorship resistance.
Inverting the web
On the Peer Web, the always-on node, likely hosted by a third party, must be an unprivileged node. What I mean by this is that it must not know/have the paraphrase (and the secret keys derived from it) that the nodes that are physically under your control do. The always-on node acts as a signaling service, as a dumb relay (for example between browser-based nodes and native nodes) and as a software delivery mechanism for browser apps.
That last point requires clarification as its implications run contrary to the traditional best practices of web development. In traditional web development, sites are rendered on the server and delivered to the client. In the earliest days, web sites were entirely static. Then, we started adding functionality through JavaScript. This functionality was implemented as enhancements to the page (“progressive enhancement”). While this traditional model has been upended in recent years with the evolution of so-called single page apps (SPAs) that are rendered on the client using JavaScript, traditional best practice for the Centralised Web still holds that if your site doesn’t work without JavaScript, it is broken. For the Peer Web, we invert that rule:
On the Peer Web, if your always on node works without JavaScript, it is centralised (and thus broken).
Trust but verify
An always-on node on the Peer Web is an unprivileged and untrusted node. Thus, when used to deliver an application to a browser, we must be sure that it is delivering exactly what we expect from it and nothing malicious. The way we do this is to make sure that we can verify the content that it serves. And that means that that content must be predictable. The method we use to verify the content is a combination of subresource integrity of the script and third-party verification of the integrity hashes in the HTML (e.g., via a browser extension). What this precludes is the implementation of any server-side implementation of app functionality. All browser node functionality must be implemented client-side.
The importance of the above paragraph becomes clear once you realise that aspects of a person’s identity are tied to pieces of information that only they possess and which they enter into their trusted nodes, including browser nodes. These passphrases (and the secret signing keys and encryption keys that are derived from them behind the scenes) must be kept secure as they are what secure the integrity of the person they belong to in the digital/networked age.
On the Peer Web, a strong passphrase (eg., a randomly-generated Diceware phrase with >= 100 bits of entropy) is the key to a database that’s associated with a domain name you own as well as an uncensorable identifier (a hash that addresses your database within a distributed hash table).
In terms of usability, we can (and should) carry forward familiar concepts and flows from the centralised world (such as “sign up” and “sign in” and “authorise device/node”) that abstract away the more confusing technical details of decentralised authentication and replication.
Building bridges
I mentioned earlier that the always-on node acts as a “dumb relay.” In this capacity, the always-on node works not just as a means to ensure findability and availability but also as a bridge between the browser and native apps (including, possibly, operating systems).
In technical terms, the always on node bridges between native and web by replicating with native nodes over TCP and bridging with browser nodes via WebSocket. Native nodes, of course, replicate among themselves via TCP, and browser nodes via WebRTC. The end result, from the perspective of the people who use such systems as everyday things, is a seamless and continuous experience across their various devices and between their browser and native apps.
I have begun to explore the genera architecture outlined here with a series of spikes in a project I’m calling Hypha (RSS, Source).
Hypha: a work-in-progress.
Hypha
The core technologies I’m basing Hypha on are the hyper* modules (hypercore, hyperdb, and hyperdrive) from the Dat project. While Hypha is the logical evolution of Heartbeat, and the continuation of our work alongside the City of Ghent last year on the Indienet project, it is an evolution of (and differs substantially from) both in many details.
Heartbeat, while it had the same overall goals, was limited in scope, design, and execution. It had a single privileged centralised node for signaling whereas in Hypha you get your own unprivileged always-on node. Heartbeat was also limited to a single device; Hypha is not. There are, also, aspects that are very similar. Heartbeat had a kappa architecture and replicated data using a modified version of Syncthing. Hypha will implement a kappa architecture (see this workshop and the design of Cabal for references) and use hyper* for replication. However, unlike Syncthing, which is a file backup tool that I was trying to shoehorn into being the engine of a decentralised web, Dat and the hyper* family are designed to solve the same problem I’m tackling. And, unlike Heartbeat, Hypha is not limited to a single platform and has both the browser and native apps as first-class citizens.
Hypha is also an iteration of our Indienet project with the City of Ghent last year (here’s a talk I gave at Eurocities describing it right before preparations for a new right-wing local government meant that our funding was cut for the project). The Ghent experience made me realise a number of things. First, that anything politically-funded is fragile and should be treated as such (as we should remember before putting our trust in city governments while designing systems. Your government may be progressive today and fascist tomorrow. Does the design of your system protect people against the worst-possible government that might ever come to power?) It also made me realise that I must follow a first-principles approach and that I need to take my time to fully grok and implement the fundaments of this system. (Specifically, that I cannot lead a team to think through these aspects for me.) In other words, slow down and (re)start small. That’s the approach I’m taking with Hypha and it is starting to really pay off. What Hypha will become is slowly evolving from a series of iterative spikes.
For any interested developers out there, the latest completed spike is Multiwriter-2 (Source), where I implemented and integrated an end-to-end encrypted secure ephemeral messaging channel that is used to provide seamless device/node authentication. The latest work-in-progress spike is Persistence-1 (Source), where I am now moving from using random access memory as storage to random access IndexedDB in the browser and random access file on native. This iteration is also going to be the first time I implement a flow similar to what will eventually be used.
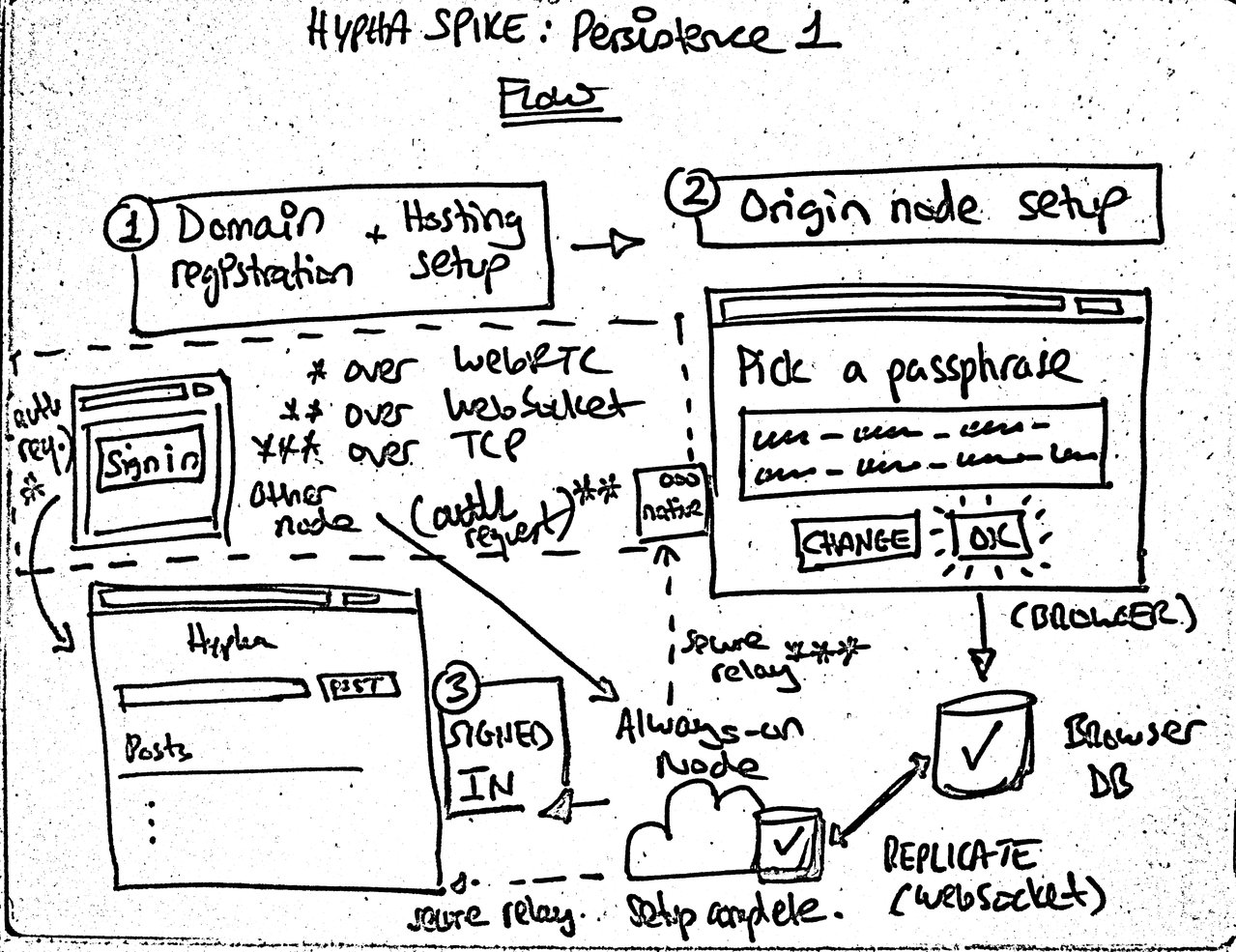
The Persistance-1 Spike will get us closer to the actual flow in Hypha proper.
Hypha has no release date, no big reveal, and makes no promises. It’s what I’m calling my current work on as I continue to tackle the general problem I’ve been working on in one shape or other for the past six years. At this point, I’m not looking for collaborators as I’m still working through the basic concepts on my own. But if you’re a developer and you want to start playing with some of the code, please do. Although it would probably be a more useful introduction to the space if you take the Kappa Architecture Workshop and the Learn Crypto Workshop (find my work files here), start hanging out in the Dat chat room, exploring the Dat project, checking out the Dat blog and reading through the excellent documentation and reference material.
We’re at the very beginning of the Peer Web (PC 2.0) era. I saw yesterday that my blog, which is also available over Dat (use Beaker Browser to view that link), is currently the most popular Dat site on the Internet. Out of the ten that the researcher was able to find by scouring the top 2.4 million domains, that is. And Ind.ie’s web site (dat link) is the third most popular. That tells you just how nascent this all is. If you want to help write the next chapter of the Internet, now is the time to pick up your quills and join us in hyperspace.
As always, if you want to support my work, you can help fund our not-for-profit, Ind.ie, or just tell your friends about Better Blocker, the free and open source tracker blocker that Laura and I develop, maintain, and which we sell on macOS and iOS.