Hypha Spike: Persistence 1
Note: Unlike previous spikes, I’m leaving this spike in a non-functional state and instead starting from scratch on the main project. See post-mortem
Source
- source.ind.ie/hypha/spikes/persistence-1 (canonical location)
- Github mirror (pull requests, issues, etc. welcome)
Scope
Following on from Hypha Spike: Multiwriter 2 this spike aims to:
- Use persistent storage
- Evolve the sign up / sign in processes accordingly
Design
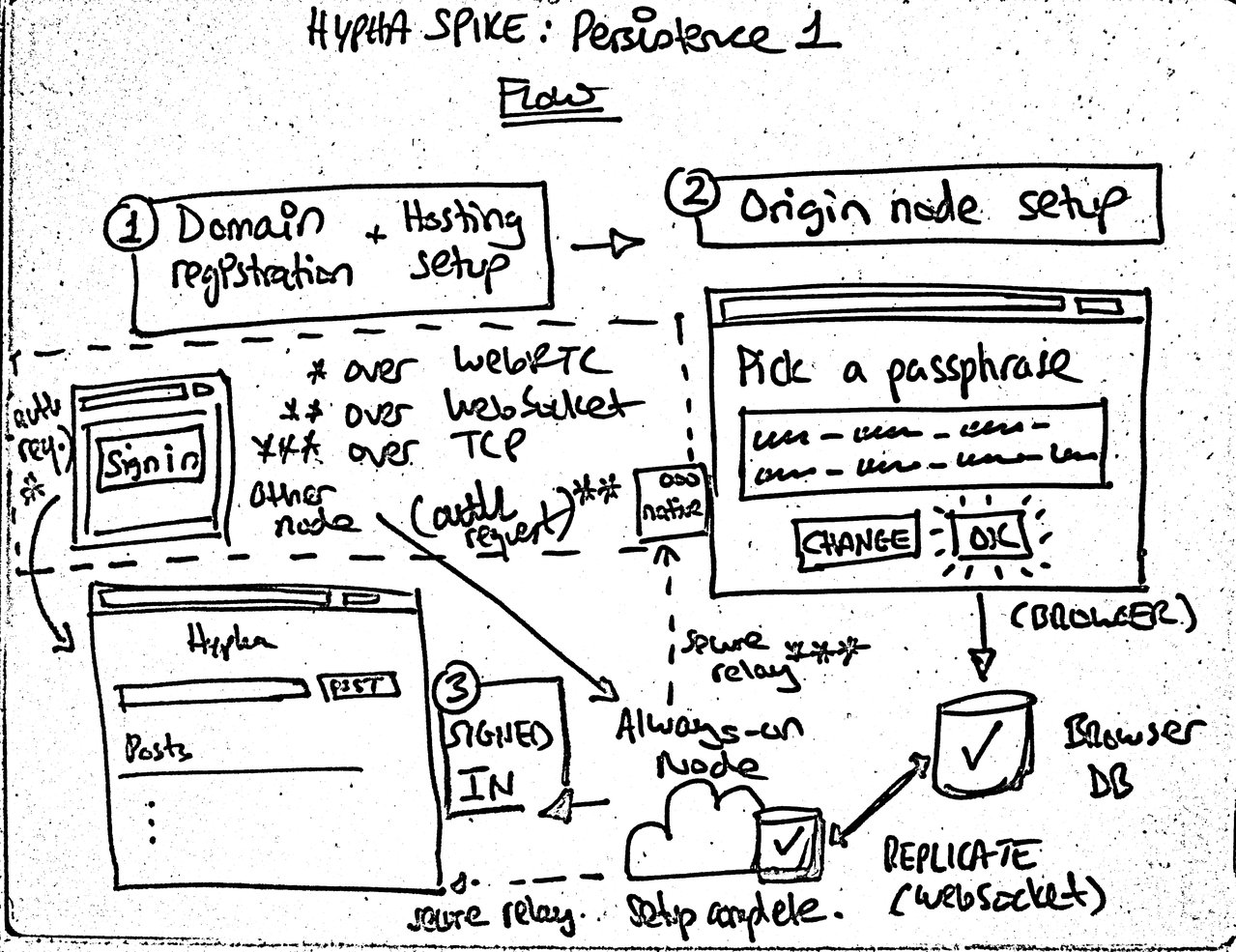
Implementing persistance and getting closer to the actual flow.
-
Domain registration + hosting setup (out of scope, although see Hypha Spike: Deployment 1)
-
Origin node setup: an uninitialised always-on node is hit: the setup page is delivered. In browser (and, later, also via native app), person chooses a generated Diceware passphrase. The node that the person is using becomes the origin node.
-
Origin node replicates to the unprivileged always-on node via WebSocket. At this point the always-on node is initialised and set to replicate that particular database only.
-
The person sees themselves as signed in and can post entries. (For the purposes of this spike, simple text-only public posts – just so we have some data and can see things replicate.)
-
On some other node (browser or native), person accesses the domain. They can see the public posts as we set up a read-only local database and replicate them. We know which database to replicate based on a Dat-DNS lookup via the .well-known/dat location on the domain of the always-on node. See security note 1.
They do not see the positing interface. Instead, they see a passphrase field (not shown in above whiteboard sketch) and a sign in button. Entering a passphrase creates the deterministic keys and proceeds to request authorisation via the secure ephemeral messaging channel. The person is asked to authorise the request from an existing node (e.g., the browser(/native app*) they set up from). _* out of scope for this spike._
-
On a previously-authorised node (e.g., the origin node), the person approves the authorisation request.
-
On the newly-authorised node, the person sees the posting interface and can now write to the database.
Iteration plan
- ✔ (tag) Implement random-access-idb in the browser node.
- ✔ (tag)Implement random-access-file in the always-on node.
- Update interface and flow according to the design notes above.
Future plans
- Create a higher level Hypha authentication library with a simpler API that abstracts away the messaging aspect (@hypha/auth)
- Tie in with Hypha Spike: Deployment 1
- Add options to interface to selectively enable replication over WebSocket or WebRTC or both for testing.
- Clean up the interface and carry out some general housekeeping on the code.
Upcoming spikes
- multiwriter hyperdrive (carried over from multiwriter-2)
Development notes
-
Although the random-access-storage project states that the interfaces of the various random-access-* projects are the same, this is not entirely true for random-access-memory and random-access-idb (IndexedDB). This tripped me up while migrating from one to the other. I noted the discrepancy and suggested that we document it.
-
If you’re testing IndexedDB persistence on Firefox, make sure you are not browsing in private mode as it will fail silently.
-
I’ve decided to use the hostname as the identifier of the browser node database. As browser nodes will have to be served from a domain and as they will have the domain available regardless of whether they are online or, later, offline (PWA support), it feels like the correct identifier to use.
-
Initial load flow:
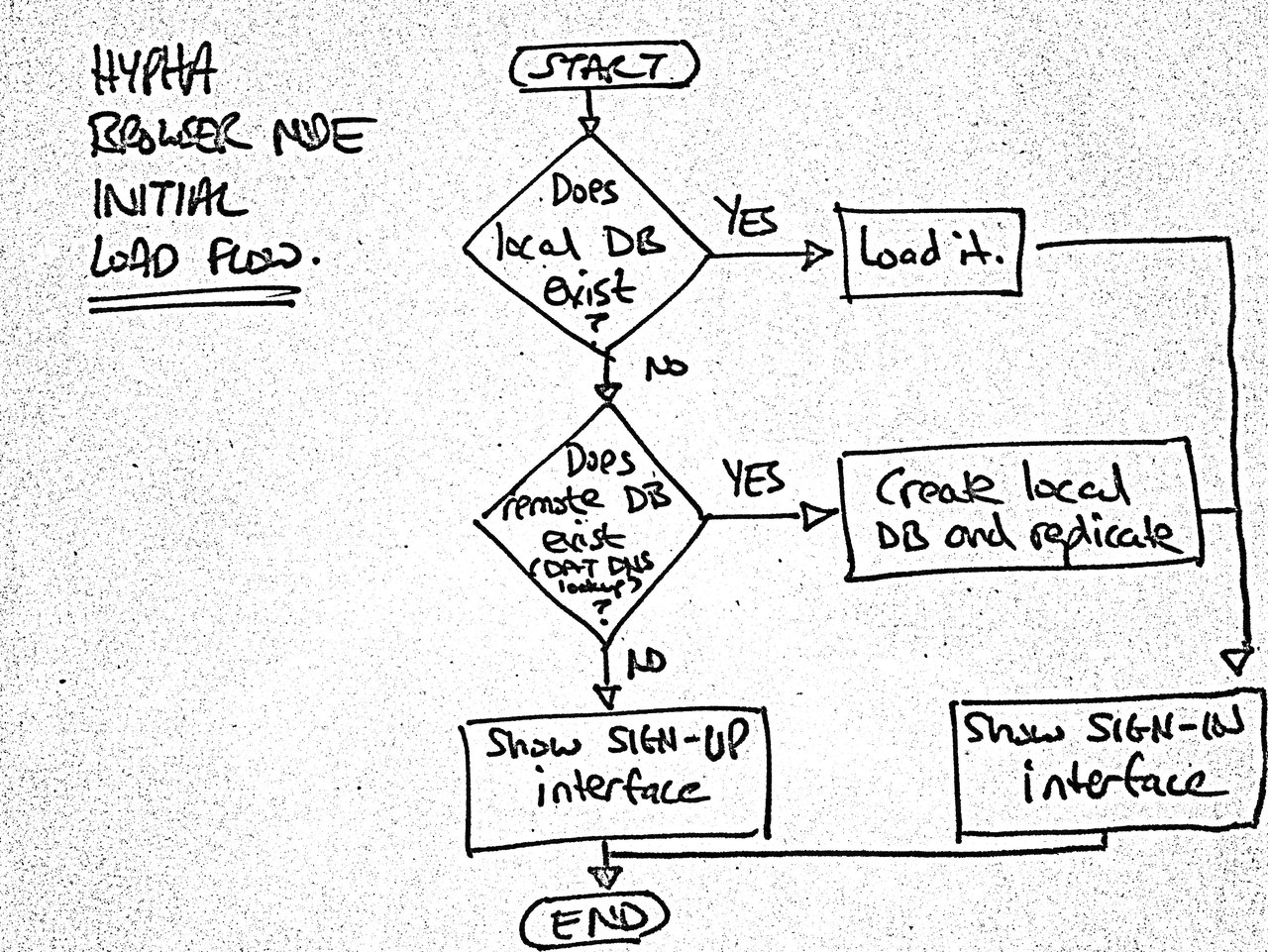
Initial load flow for browser nodes.
-
Regarding sign-ins: if a database is lost for any reason, we will need to recreate it. So I’ve reopened the reproducible writers pull request I was preparing for hyperdb. Update: On further thought, having a reproducible unique ID for browser nodes is a hard problem and this feels like a premature optimisation right now. Instead, I realised I can separate the sign in process (the provision of the passphrase) from the database creation (something that also becomes clear once the flow accounts for unauthorised, read-only nodes – i.e., people who are just browsing your public content). Also, we can encrypt the local secret key and persist the encrypted key in the browser. The combination of these should mean that we can get away with sacrificing a writer if the database is lost and create a new one instead. We’ll need to keep an eye on real-world usage down the road but it doesn’t feel like this should be a showstopper. The Multiwriter DEP, for example, states that “The design should easily accommodate dozens of writers, and should scale to 1,000 writers without too much additional overhead.” I will write a separate post to document the sign up/sign in and database creation flow.
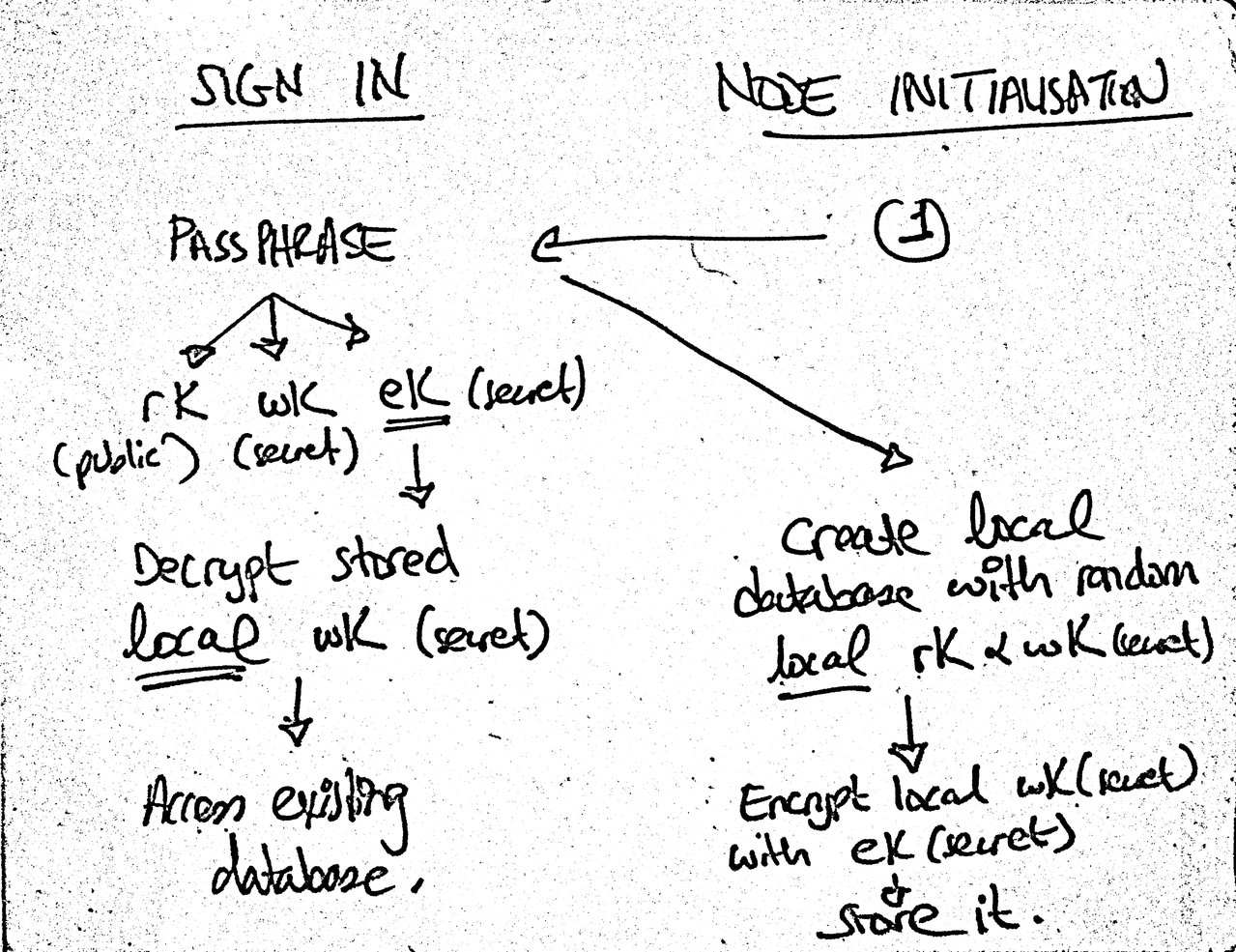
Separating sign in from database initialisation. Legend: rK = read key (public key), wK = write key (secret key), eK = (symmetric) encryption key (secret).
-
I’m also thinking that the origin database shouldn’t be used for anything else but to create and authorise a secondary writer.
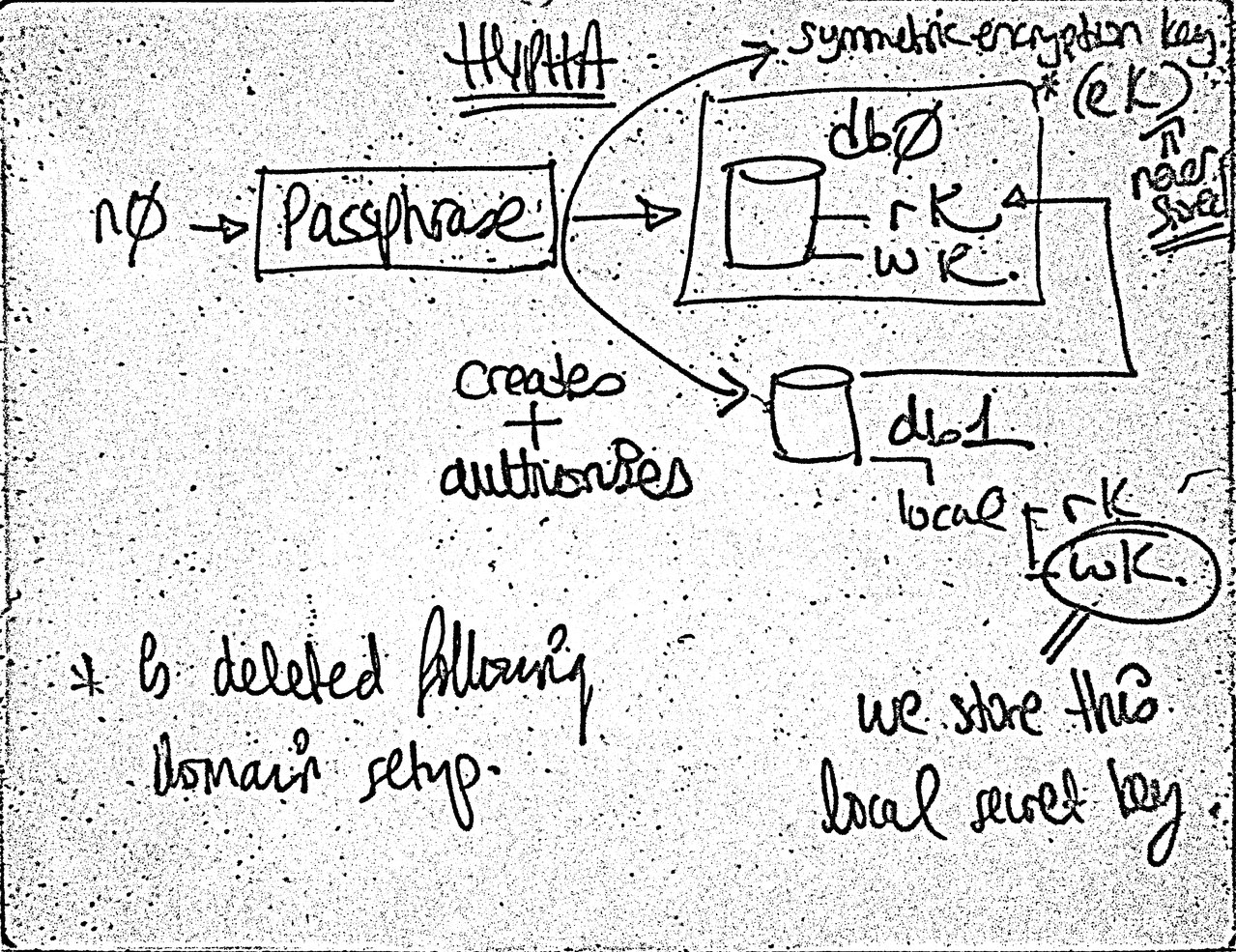
Setup flow where the origin database is used just to authorise the first writer.
-
Did some testing on hyperdb/hypercore (writer) recreation in a separate recreate-hypercore spike.
Post-mortem
Working on this spike has made a couple of things clear:
-
If I don’t want to introduce new concepts into the web experience (I don’t) and keep the flow to the traditional (sign up/sign in), I have to use two hyperdbs per instance: one signed out and one signed in:
A person is signed out if they haven’t entered their passphrase and/or their write key was not saved (unencrypted) localStorage. The latter will be an option (“keep me signed in”). When an authorised node is signed out, the write key is stored encrypted in local storage and decrypted once the person has entered their passphrase.
Since we must have the read and write key for a local writer in order to recreate a hyperdb, we cannot recreate a hyperdb when the write key is encrypted and the person has not entered their passphrase yet. In this case, we need a separate hyperdb, with a separate read and write key. This will allow us to implement the familiar (signed in/signed out) experience from the centralised web.
-
The spikes have morphed (especially during the last few ones) into iterations and have now grown to an unmanageable state. I’ve hit diminishing returns in this spike while trying to alter the core interactions. It’s time to start the project proper from scratch and using more maintainable practices. As such, I am going to leave this spike in its non-functional state and start the main project. I will still be using spikes in the future to explore specific issues but from here on, I will be iterating on the main project and on modules used by it.
Security considerations
- Regarding design step 5: Remember that the always-on node is untrusted and unprivileged. We could easily set it up so that it returns the Dat URL in the rendered source but we won’t be doing that. The unprivileged node will return unaltered source that we will verify using subresource integrity (out of scope for this spike). We will also implement trusted third-party audits of the source (this could, for example, be handled by a browser extension that compares the hashes received as well as the hash of the source code with the trusted hashes from the source code repository).
Other: See Hypha Spike: Multiwriter 2
Reference
- random-access-idb: Random-access-compatible indexedDB storage layer.
- random-access-file: Continuous reading or writing to a file using random offsets and lengths.
- DEP-0004: Hyperdb
- DEP-0008: Multiwriter
Also see Hypha Spike: Multiwriter 2 Reference