Hypha Spike: Multiwriter 1
Source
- source.ind.ie/hypha/spikes/multiwriter-1 (canonical location)
- Github mirror (pull requests, issues, etc. welcome)
Design
Following on from Hypha Spike: WebRTC 1 and Hypha Spike: DAT 1, this spike aims to explore:
- Get multiwriter working with hyperdb.
Flow
Note: the flow is currently limited by not being able to pass a custom read and write for the local writer to hyperdb. I will be adding this functionality to hyperdb in the next spike. Once that’s in there, I should be able to reduce this flow to two steps: request permission + grant permission (via an interaction familiar to anyone who has ever authorised one device from another). I did not tackle that first as I wanted to get hyperdb and multiwriter working as-is myself before anything else. Taking it a step at a time.
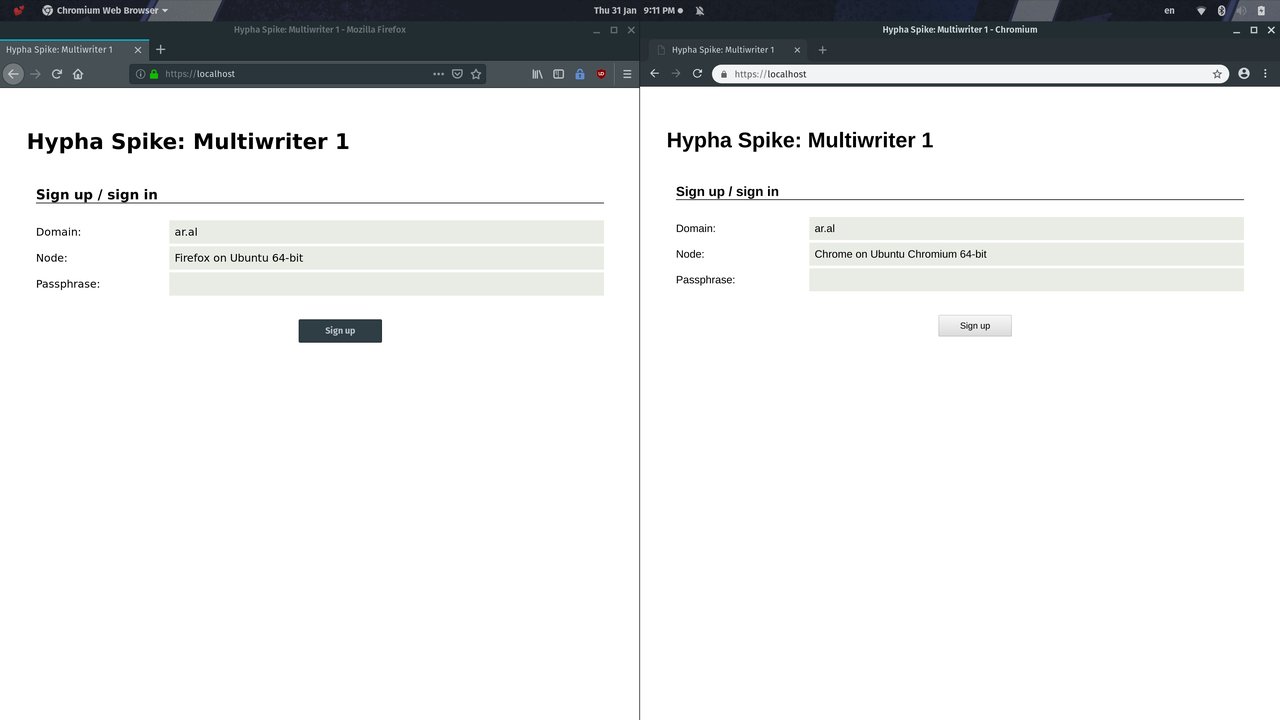
Step 1
Load app in two different browsers. Press the “Sign up” button in left browser.
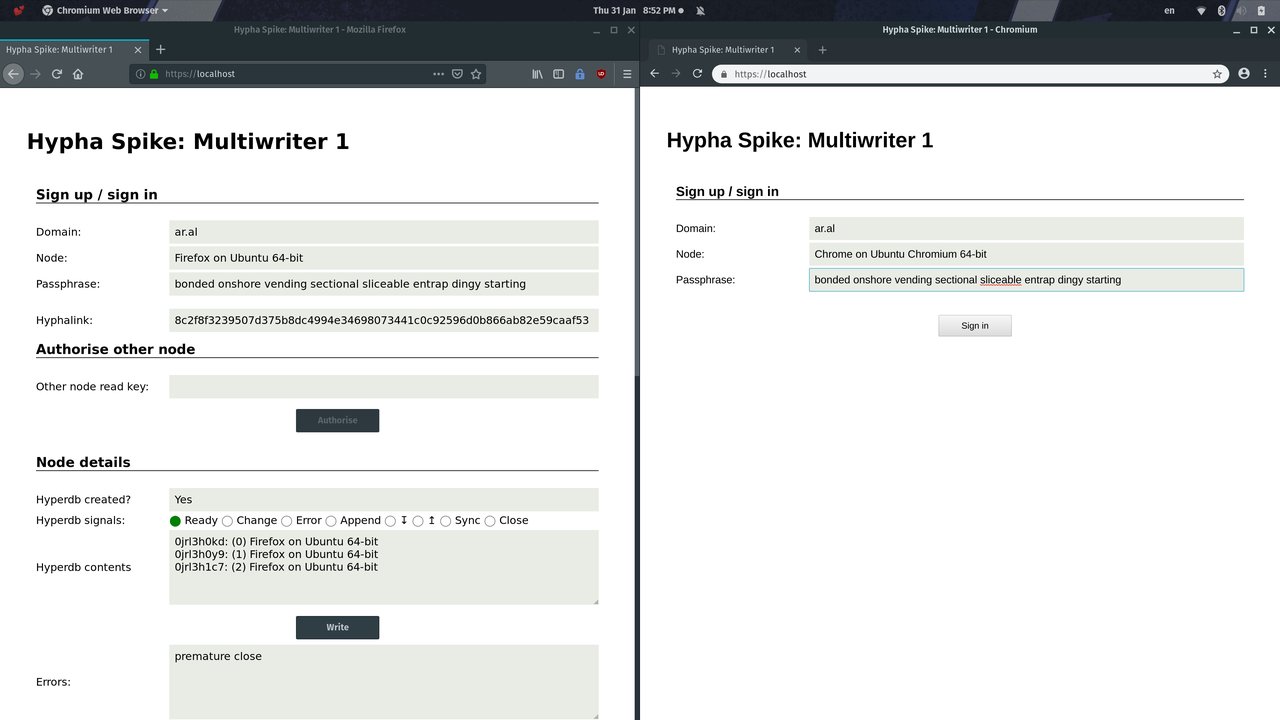
Step 2
Left browser initialises origin hyperbd and writes to it. Copy its hyphalink to the second browser and press the “Sign In” button.
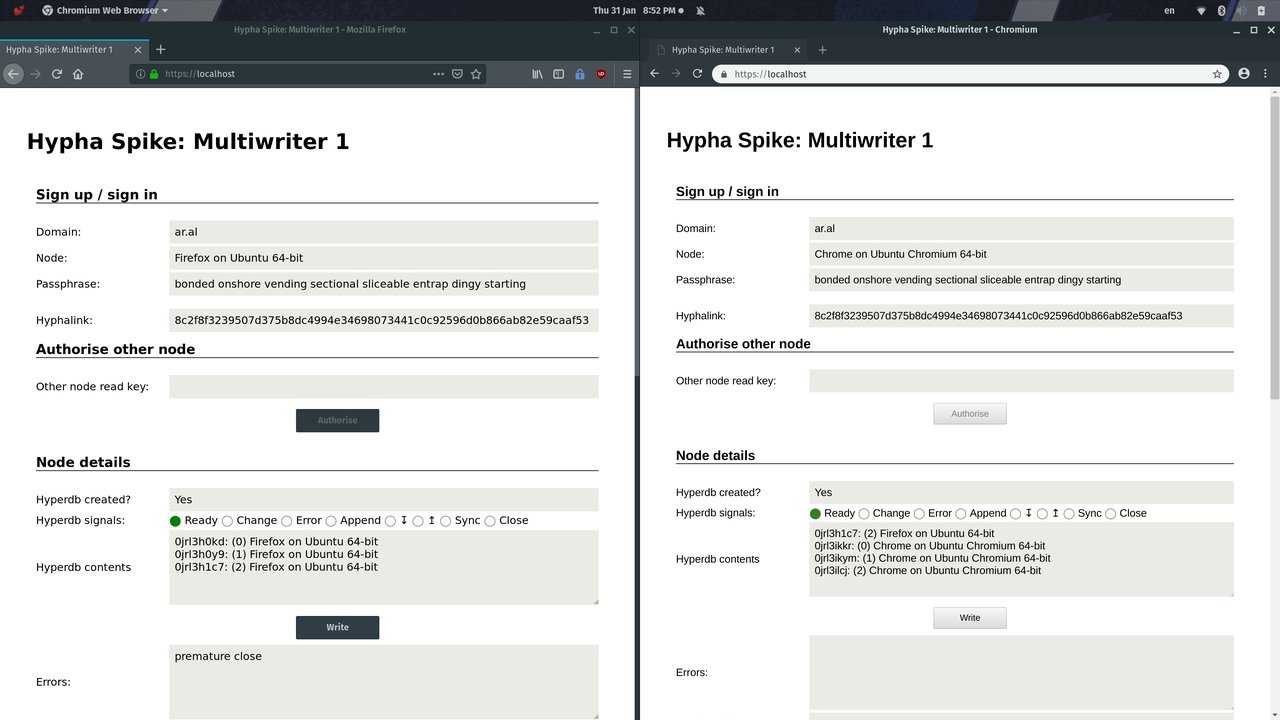
Step 3
This creates a hyperdb for the same hyphalink in the right browser. It replicates the latest entry from the left browser (see issues, below) and writes to its local hypercore but those writes do not replicate as it has not been authorised to write to the main hyperdb by the origin node (left browser).
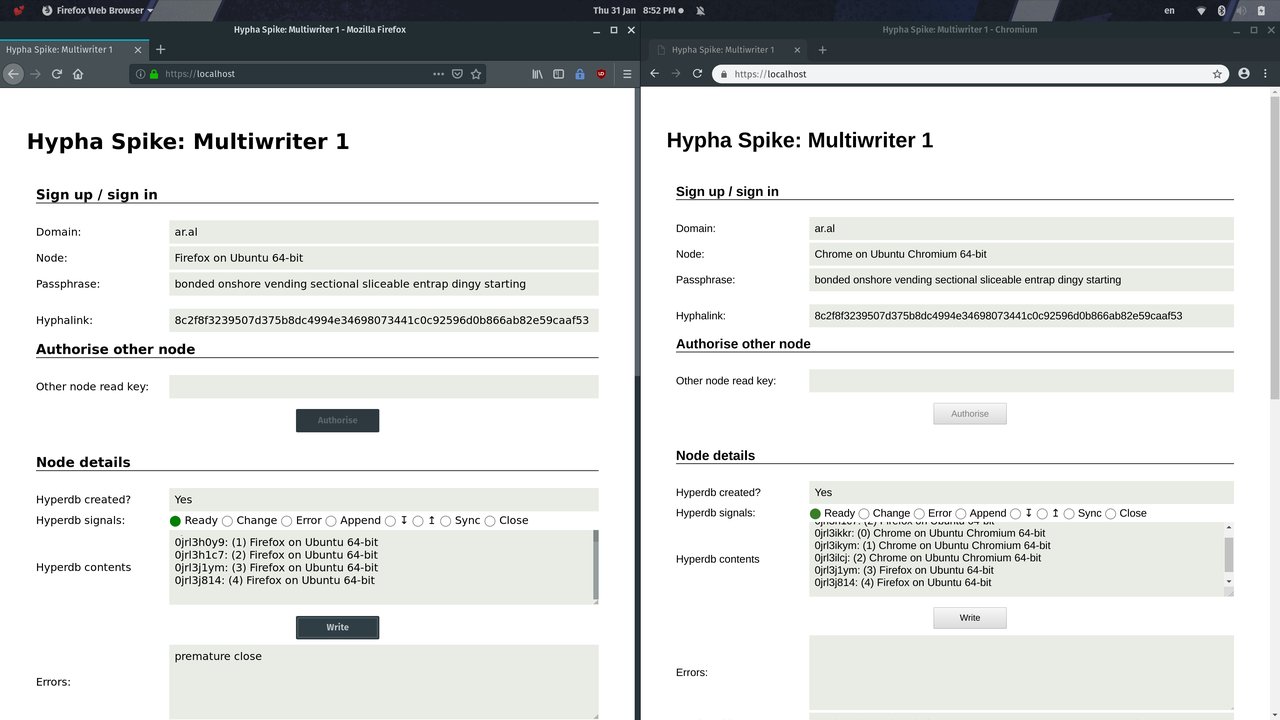
Step 4
We write a few more entries using the Write button in the origin (left) browser and note that they replicate as expected to the right browser.
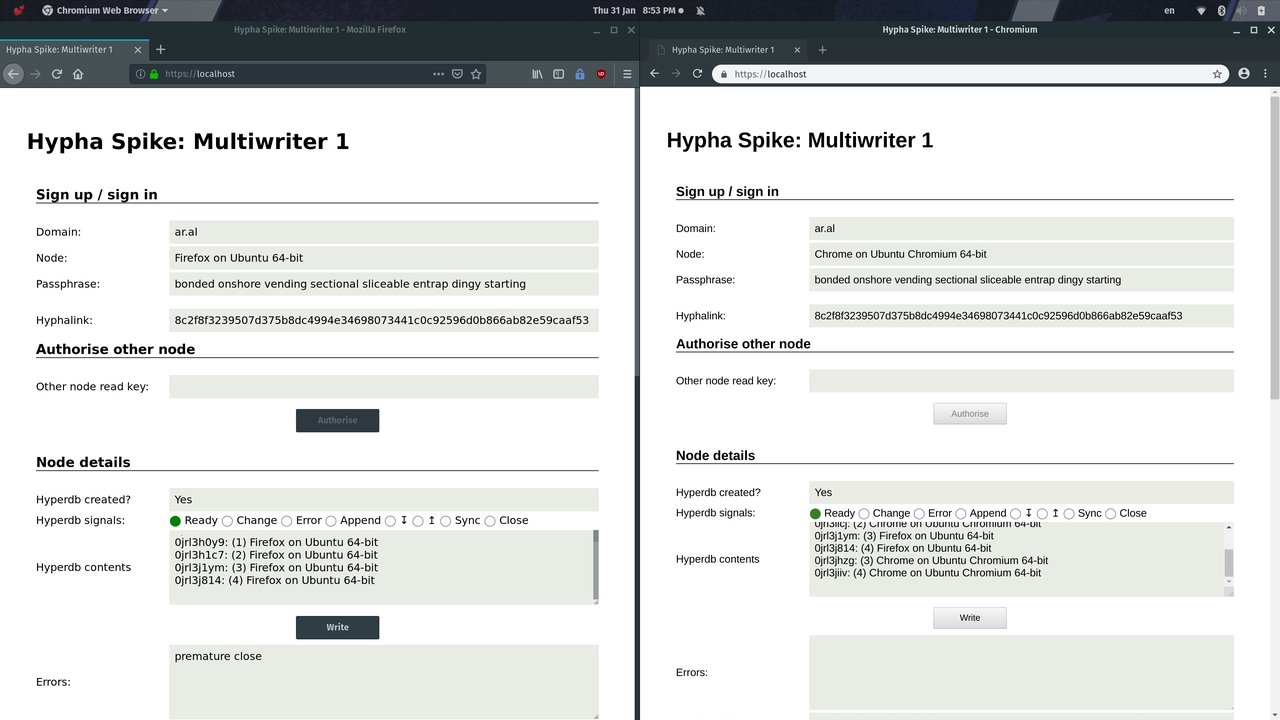
Step 5
We write a couple of new entries into the right browser and note that, as expected, they do not replicate to the origin browser because the node in the right browser has not been authorised yet.
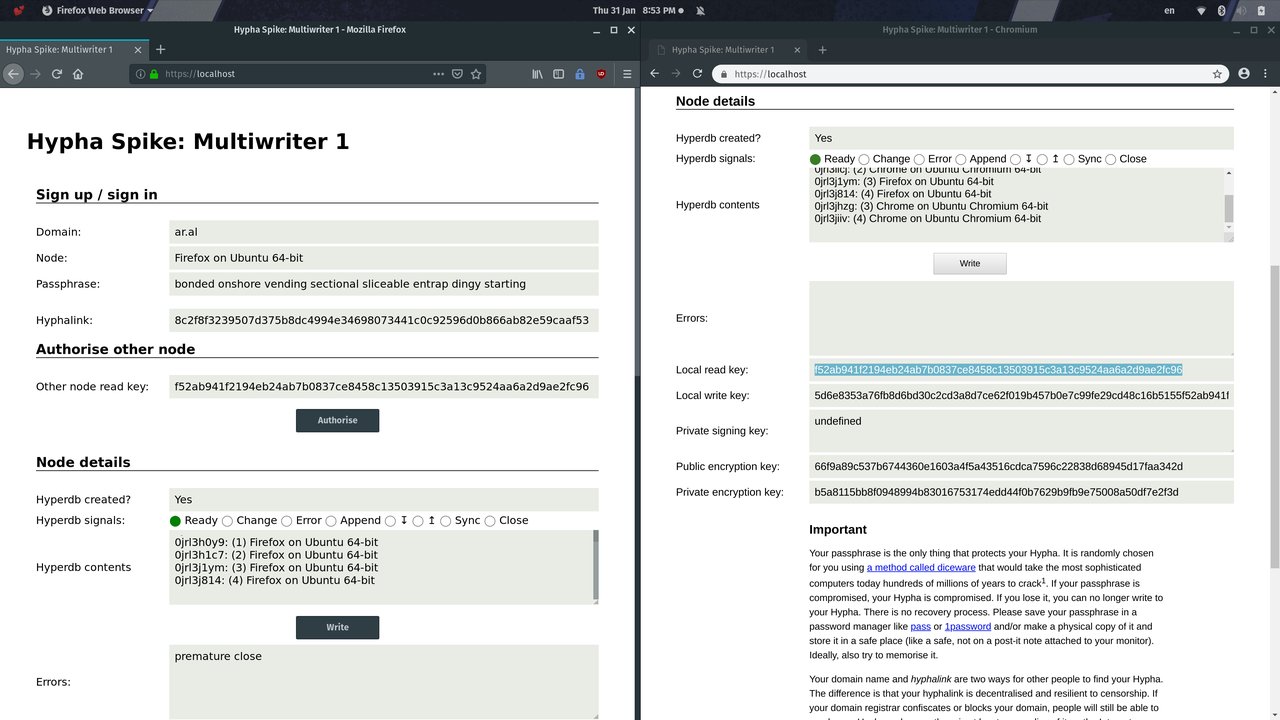
Step 6
We copy the local read key from the right browser and paste it into the Other node read key field in the left browser and press the Authorise button.
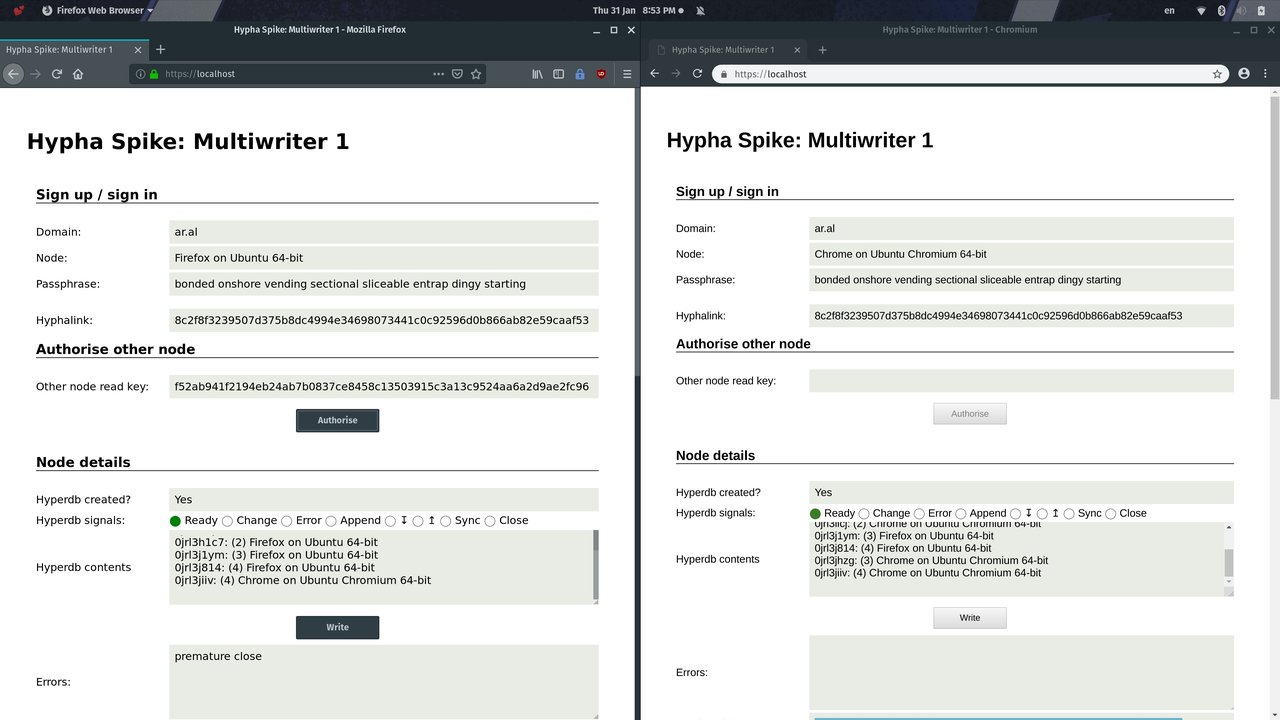
Step 7
We note that the right browser is now authorised as its last item replicates to the origin node (left browser). Again, see issues (I don’t know yet why only the last-written item is replicating and not the whole hypercore. I might have configured it incorrectly but I haven’t had a chance to look into it yet.)
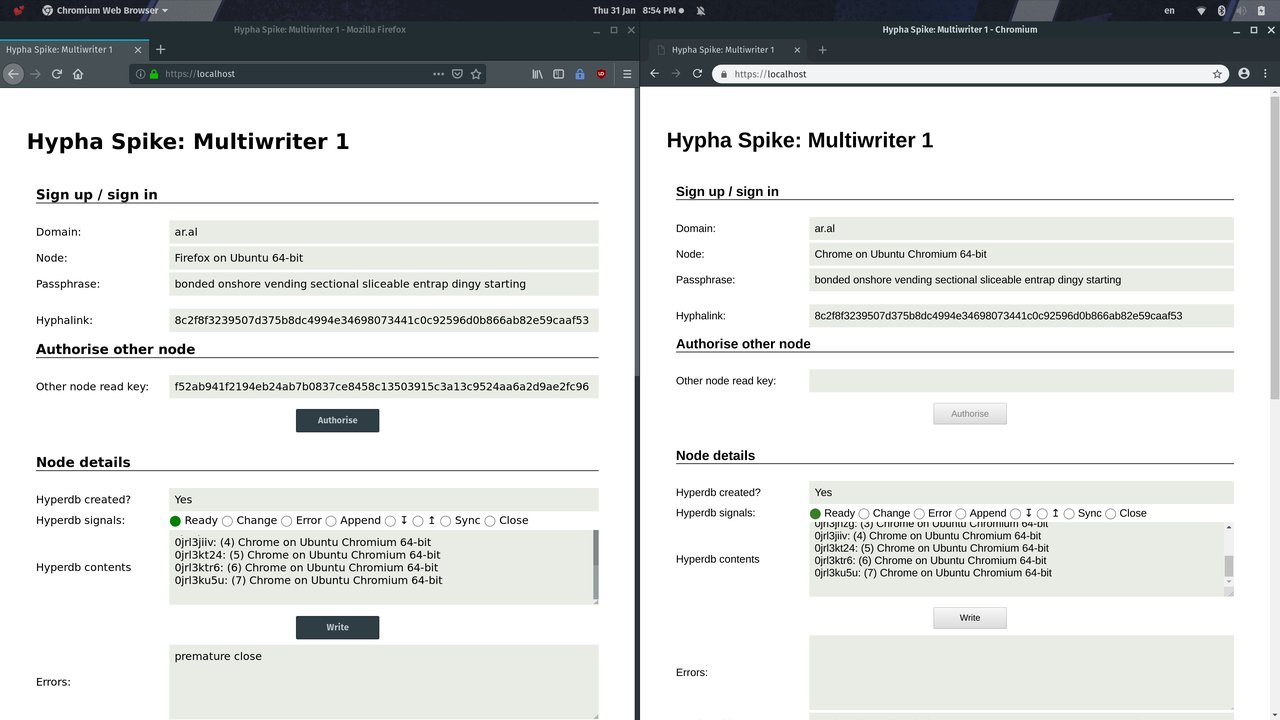
Step 8
We add a few more items to the right browser and note, as expected, that they now replicate to the origin node from the newly-authorised second writer.
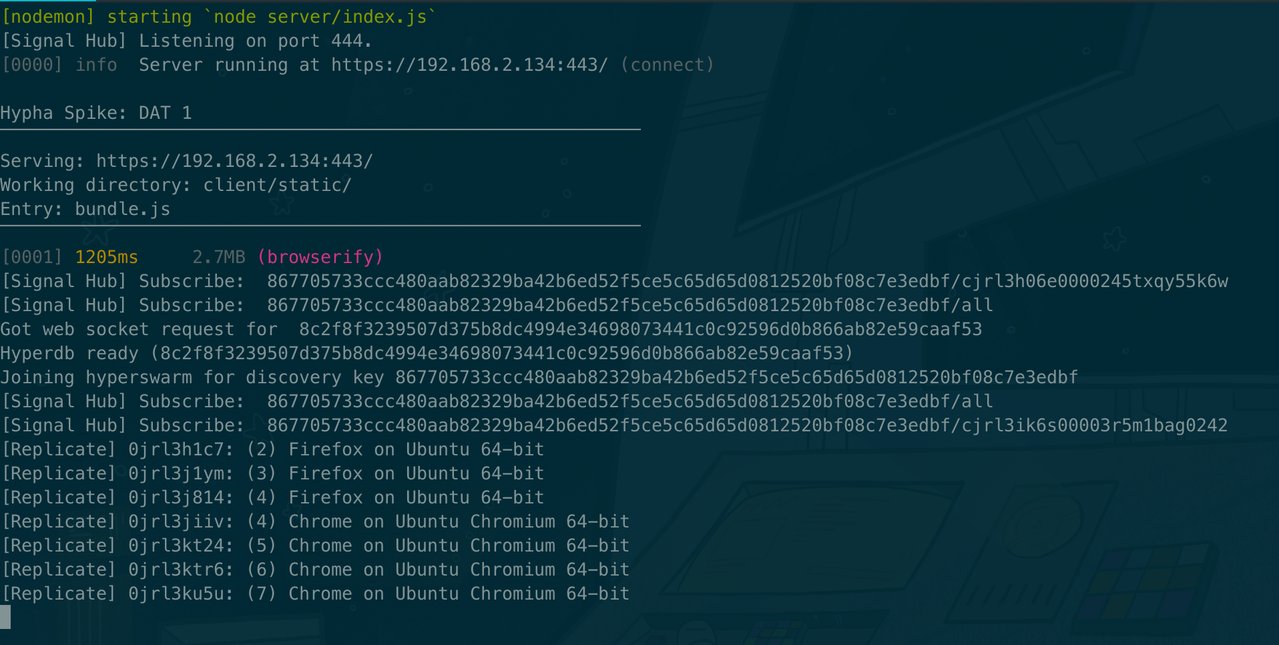
Backend
We also note that some of the entries have replicated to the always-on node over WebSocket. But not all (see issues).
Issues
To-do: investigate:
- Only the last item added before and any items added after replication begins are replicated via WebRTC (the latter requires
{live: true}in theoptions.) This does not manifest in replication over WebSocket (although, see below). - Above also appears to manifest over TCP. Why?
- Also, recently noticed that only some items are replicating over WebSocket. Why?
Notes
- Signalhub is now integrated into the server. You do not have to run it separately for WebRTC.
- Although we are not creating a persistent database in this iteration (we’re using random-access-ram instead of, say, random-access-i(ndexed)db), we must validate as if we were. The actual app will persist the database so it would never present the option to authorise a node from the same platform/app combination (e.g., Browser X on Platform Y). What this means practically is that you must test with two different browsers when testing on the same machine.
Iteration plan
-
✔ (tag) Integrate Signal Hub*
-
✔ (tag) Get multiwriter working with hyperdb automatically generating the local key material and with manual local key copy/paste between web clients
-
✔ Mirror the spike to GitHub
This is about as far as we can come with the current state of hyperdb.
Once this is working, I have to extend hyperdb so that you can specify your own keys for the local writer so that we can have reproducible keys for writers.
Once that’s done, I’ll spike:
- cross-node authorisation via ephemeral messaging over hyperswarm and public-key authorisation (this can be released as a stand-alone module that can be used across projects – e.g., hyperauth)
Pushed to later iteration:
- For ‘sign-in’ feature, generate a hypercore based on the reproducible node id
- Integrate WebRTC client*
- Implement multi-writer via multifeed
* These are to make it simple for others to clone and run the spike with minimal effort.
General: document what’s necessary to implement proper multiwriter (i.e., with ability to both authorise and de-authorise writer nodes). We need to get the ball rolling on this if it isn’t already.
Upcoming spikes
- Extend hyperdb to accept a hypercore factory in its constructor
- hyperdrive
Limitations
- It’s currently not possible to specify your own key material for the root hypercore in hyperdb. This means we cannot use hyperdb out of the box with the keys generated from our diceware passphrase (Issue #158). I will be resolving this issue as the next spike.
Further thoughts on device authorisation
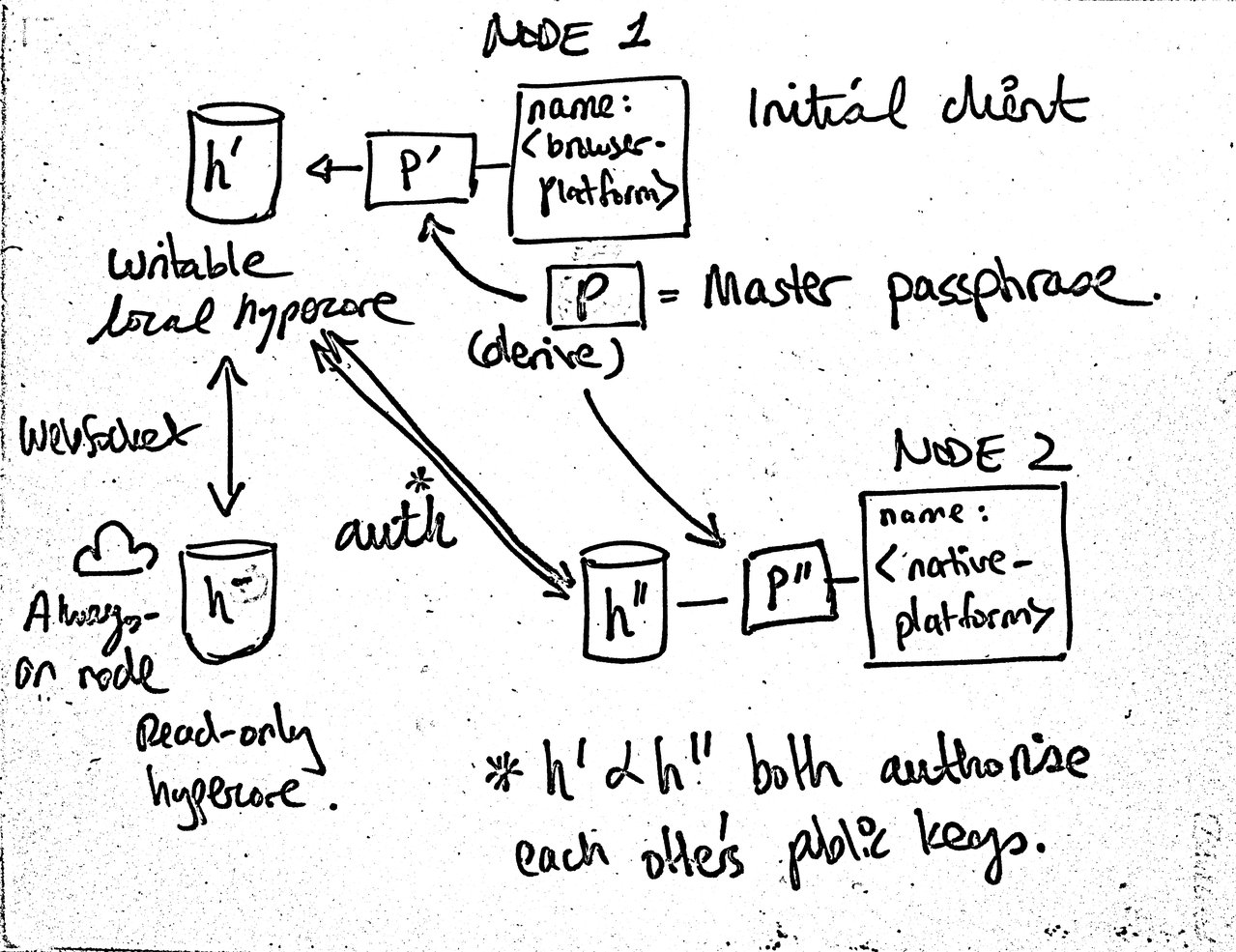
Whiteboard sketch: thoughts on device keys and authentication in Hypha
As initially posted in the Datproject discussion room:
Been giving device authorisation in multiwriter some more thought and, contrary to my initial knee-jerk reaction, I think it can be done within the limitations of the current system. It should be possible to handle lost/stolen devices as long as the write key (secret key/private key) is never stored on any device. Since I’m using key derivation from a Diceware passphrase salted with the unique domain in Hypha, this should be easy to support in a usable manner (the passphrase has to be stored in a password manager – or a brain better than mine – anyway).
So I’m thinking that the master passphrase will not be tied to any hypercore and every device’s writeable hypercore will derive its keys from the master key with the name of the device used as the salt. This means that on any node where the person enters the passphrase and the name of the device to be authorised is known, its public (and private) key can be calculated and the device authorised in the local hypercore.
If a device is lost/stolen, lack of the passphrase will disallow further writing. Of course, this requires that the device is properly secured at other layers in the stack (i.e., auto lock, password on lock, full-disk encryption).
Postmortem
- See flow, issues, iteration plan, and upcoming spikes for a good summary of how the spike went, what issues I ran into, and how I plan to resolve them.
Reference
- Hyperdb architecture
- Hyperdb authorisation guide
- The definitive replication and authorization guide (github issue)
- How DAT works
- Hyperlog-style semantics with hypercore/hyperdb?
- Multiwriter hyperdb WIP pull request
Historic links (Heartbeat – 2014)
Heartbeat was the initial precursor to Hypha. We were limited by lack of control over the replication engine we had chosen (syncthing). Other limitations were: it was single writer/device, it had a privileged centralised signalling server. That said, it basically used kappa architecture (although the term was independently being coined at about the same time) and did solve some of the same challenges we need to solve now using the Dat protocol/ecosystem. The design is very close to that of Cabal but with the addition of authentication and private messaging.
- Heartbeat pre-alpha release
- Heartbeat conceptual design
- Heartbeat technical design
- Heartbeat sequence diagrams