Hypha Spike: Aspect Setup 1
Design
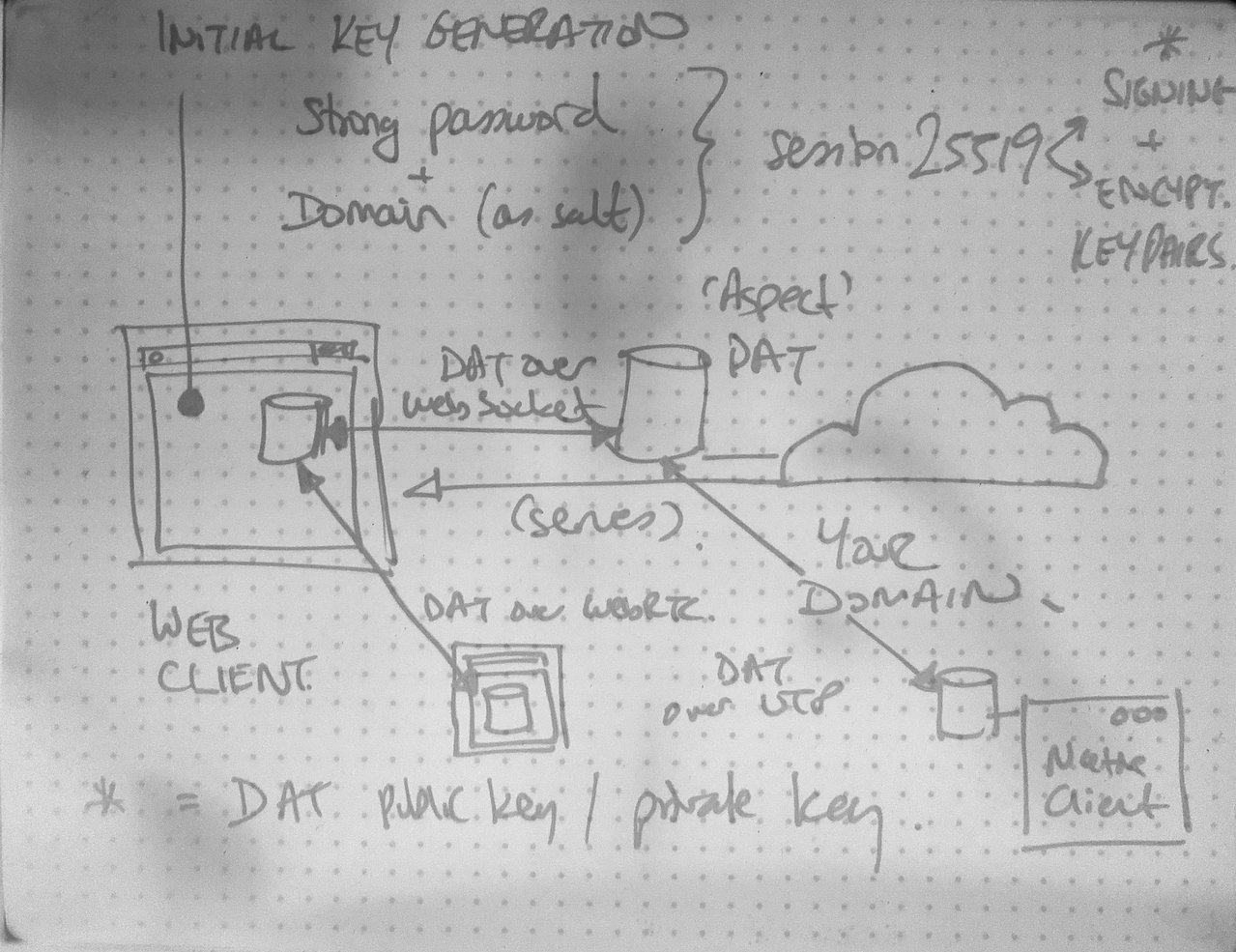
My Boogie Board notes on the general design on Hypha
Philosophy
Your identity – your self – is a sharded aggregate of information1. For an organism to have integrity it must have ownership and control over the aggregate of these various elemental shards that, combined, constitute its being.
In Hypha (subscribe via RSS), I will call these shards aspects2.
For the purposes of Hypha, an aspect is defined by a secret known only to the person who owns it.
From this secret, we derive two keys3:
- A key to obtain and read this aspect (“read key”)
- A key to write to this aspect (“write key”)
Anyone with the read key can replicate your aspect and read any unencrypted information in it. The root of an aspect is public information. It is how other people find you.4
Your write key is used both to add to your aspect and, for private information, to encrypt it.
The owner of an aspect can write to it from any device that they own.
The aspect acts as a root index that links to both public and private collections of data. These collections may be interactions and include contributions by multiple people on multiple devices.5
Scope
This spike will focus on the basics of aspect setup:
- Enter strong password on web interface
- Generate ED25519 signing keys (read key and write key6) from password (via Argon2)
- Generate Curve25519 encryption keys from signing keys
Generate root aspect DAT archive using the keys generated in Step 2.Replicate the aspect from a separate node to test that it works as intended (e.g., command-line DAT running on a native client)
Steps 4 & 5 moved to the next spike (see postmortem).
All key generation happens on the client. The untrusted server (unprivileged always-on node) must never have the secret key.7
This spike is related to the Indienet publickey auth spike from last year. However, I no longer feel that publickey authentication is necessary for the client. The DAT archives are our source of truth, they’re what we replicate, and they already handle authentication. Visibility of sensitive data does not have to be controlled at the web interface level but handled through end-to-end encryption. I am therefore also leaning towards the web interface being a single-page application.8
Spike notes
Iteration 1
Iteration 2
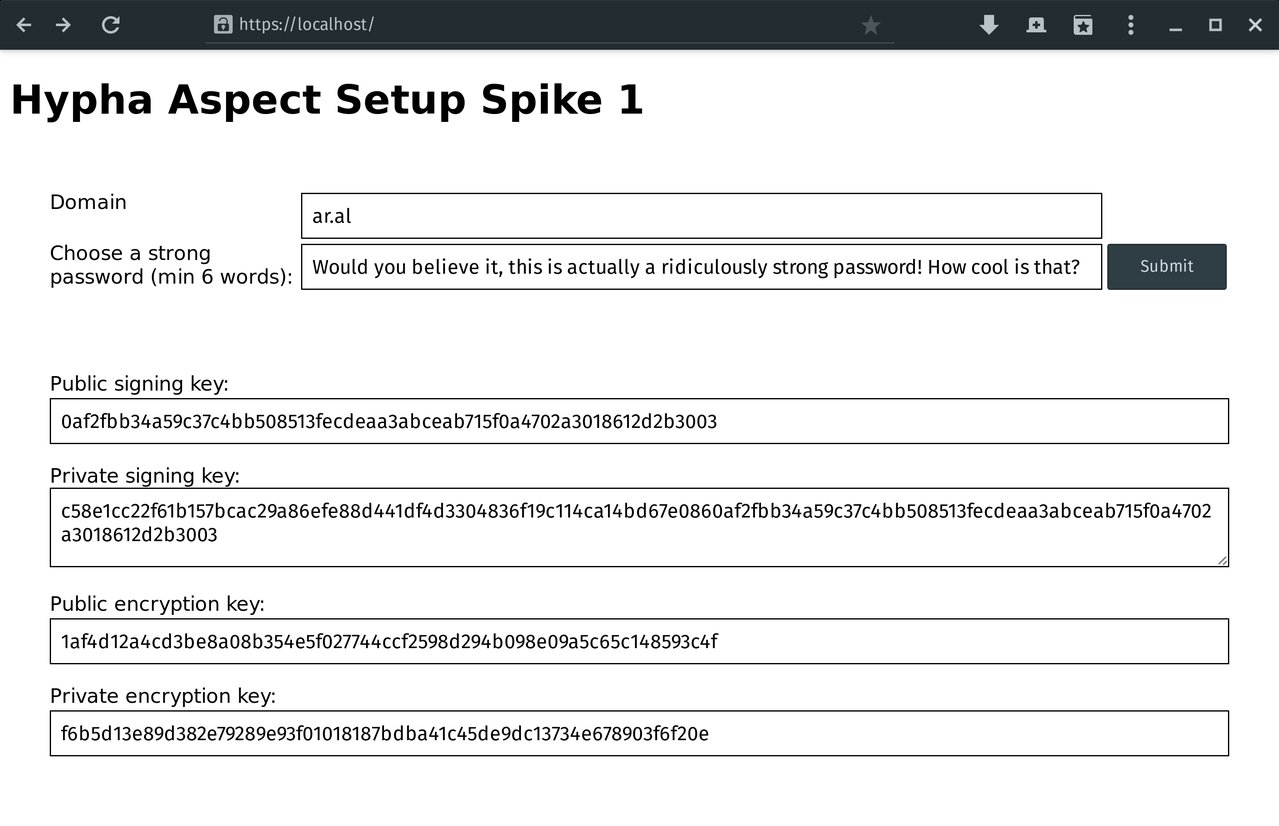
Screenshot of Iteration 2
(Master branch.)
- Use session25519 to generate the DAT keypair from a strong passphrase and the domain name as salt. Since domain names are globally unique, this is a strong salt, regardless of the fact that it is not random and could be short (e.g., ar.al).
Postmortem
- I’m going with the approach in Iteration 2.
- In the next spike, I will look at generating a DAT using the generated key material and replicating it to the always-on node via web socket.
Also see
Update: (2020-03-16) All Indienet links removed as that project is now over and we no longer own the domain. Our work continues at Small Technology Foundation. See Site.js and our ongoing research and development.
-
Indienet general cryptography policy
-
Indienet security spikes (docs, source)
-
Indienet configuration information docs
References
- How to ED25519 keys work?
- Salted password hashing: doing it right
- Key generation in minilock
-
I include biological aspects in the definition of information because our biology is also, at its fundaments, information like all else. ↩︎
-
In DAT terms, an aspect corresponds roughly to a multiwriter/multifeed hypercore collection. Neither are entirely fit for purpose in their current state although the former is a better fit for implementing a root aspect while the latter is better suited for implementing individual/group interactions (see kappa architecture). ↩︎
-
This is an ED25519 keypair. The public key is the DAT read key. From the signing keys, we also generate Curve25519 encryption keys. ↩︎
-
On your always-on node, it is analogous with your domain name. That said, and crucially, it also exists separately from your domain name (which is still a centralised and commercially-governed identifier). Your read key (more precisely, its hash, which we call the discovery key) is the canonical address for your aspect. Even if your domain name changes/goes away, your aspect will remain as long as at least one host is available on the network for it to be found and replicated from. ↩︎
-
Each collection/interaction is also a multifeed kappa architecture data store. ↩︎
-
While both the read and write keys are considered secrets for collections/interactions, for the root aspect, the read key considered public. It is possible to create a fully private aspect by not linking it to a domain name and not advertising the read key but that is not an initial use case for Hypha. It would be interested to see how it could be implemented with a native DAT browser (currently, Beaker Browser). ↩︎
-
It’s outside the scope of this spike but for future reference: We must protect the system from Evil Host/Evil App Store (or Evil Maid at Good Host, etc.) attacks. Since the setup of the private key happens on the client and must stay on the client unless we are to compromise all security and privacy of the system, we must ensure that the client is not compromised. For native clients, this can be achieved via combination of open source and reproducible builds. For web clients, we can use subresource integrity along with third-party validators/a web of trust. ↩︎
-
This is because the always-on node/web interface must be an unprivileged node. While the core of that requirement concerns the node not having the person’s secret, it also applies to not privileging it through additional functionality. I often say that we are building a bridge between the centralised web (the Mainframe 2.0 era) but what I’ve so far failed to state is that this is a one-way bridge. The goal isn’t to encourage travel in both direction but travel from Mainframe 2.0 to PC 2.0. So it makes sense to invest as much effort as possible in the forward-looking (native) clients physically owned and controlled by everyday people that we are trying to move them towards instead of the bridge itself. The bridge is essential but it is a means to an end. ↩︎